926
カメラ1台で多人数の全身の動きを3Dモデルで復元する技術 背景の3Dシーンも一緒に再現 levtech.jp/media/article/… 静止した単眼カメラ1台から撮影した映像内の複数人の3次元姿勢,全身形状を連続で予測する機械学習モデル。各人の奥行が正確でオクルージョンも対応,足が床を突き抜けたり浮いたりが少ない
927
脳に埋め込んだ電極で「発話内容」を読み取りテキストと音声に変換する技術 1分62英単語の高速出力に成功 levtech.jp/media/article/… ALS患者さんが画面の文章を発話しようと口が時折少し動き理解できない声を発しているが,口を動かす脳の指令を電極で記録し深層学習で解読して発話内容をテキスト出力。
928
画像生成AIが「トレパク」していた? 学習画像と“ほぼ同じ”生成画像を複数特定 米Googleなどが調査 itmedia.co.jp/news/articles/… 1億7500万枚中109枚が学習データとほぼ同一の画像が出力された。個人特定できる顔写真や商標登録ロゴも含まれる。Stable Diffusion,Imagenで調査。上図が元,下図が生成画像

929
映像内の犬を猫に変えられるAI テキストのみで動画編集が可能 Googleなど「Dreamix」開発 itmedia.co.jp/news/articles/… 文章に応じて動画内の被写体の変更,動く向きを変える,背景を燃やす等多様な編集が行える拡散モデル。静止画像1枚からその中を動かす事も可能。
930
文章で3Dキャラクターの動きを細かく操作できるAI NVIDIAなどが技術開発 levtech.jp/media/article/… 入力テキストに応じて物理ベースの3Dキャラクタアニメーションを生成する。歩く走るターゲットを蹴る剣で切るなどデータセットにない動作も行える。
931
「自分の絵を画像生成AIから守る」――学習される前に絵に“ノイズ”を仕込みモデルに作風を模倣させない技術「Glaze」 levtech.jp/media/article/… ネット公開前に敵対的な摂動を注入。学習されても全く違う画像が生成される。図左2列が元画像,右2列が妨害後画像。プロ絵師約1000人の90%以上が保護成功と評価

932
スマホ(単眼カメラ1台)で撮った映像から3Dアバターを詳細に再構築するAI「Vid2Avatar」 ゆったりした服も再現 moygcc.github.io/vid2avatar/ Seamless有料ジャーナルより抜粋 buy.stripe.com/14k6oGac05oOcw…
933
単眼カメラ1台で撮影した映像から「動く人物3Dモデル」と「カメラ位置」を抜き出す技術
Decoupling Human and Camera Motion from Videos in the Wild vye16.github.io/slahmr/
934
ざっと落書きした絵をリアルな3Dモデルに変換する技術 米カーネギーメロン大が開発 levtech.jp/media/article/… セグメンテーションや手書きスケッチなどの2Dラベルマップを入力に異なる視点から対応する画像を3D合成する。ぐりぐり動かせ書き加えたり消したりして編集も行える。
935
生きた細胞を内臓に直接3Dプリント 細長いロボットを肛門から挿入、臓器上で造形 itmedia.co.jp/news/articles/… 先端が3自由度でグリグリ曲がるノズルが付いたカテーテルベースの細長いソフトロボットを肛門から挿入し目的の臓器上で生体材料を直接3Dプリントする。
936
聞き取れない声を“通常の声”に変える「人工喉」 喉に貼り付ける薄い小型マイクスピーカー itmedia.co.jp/news/articles/… 微小な声や喉頭摘出術などで声を失った方の曖昧な発話を通常の会話レベルの音量の音声合成に変換し再生する喉に貼る装置。喉付近の筋肉運動や音声振動を感知し熱音響効果で音声合成に
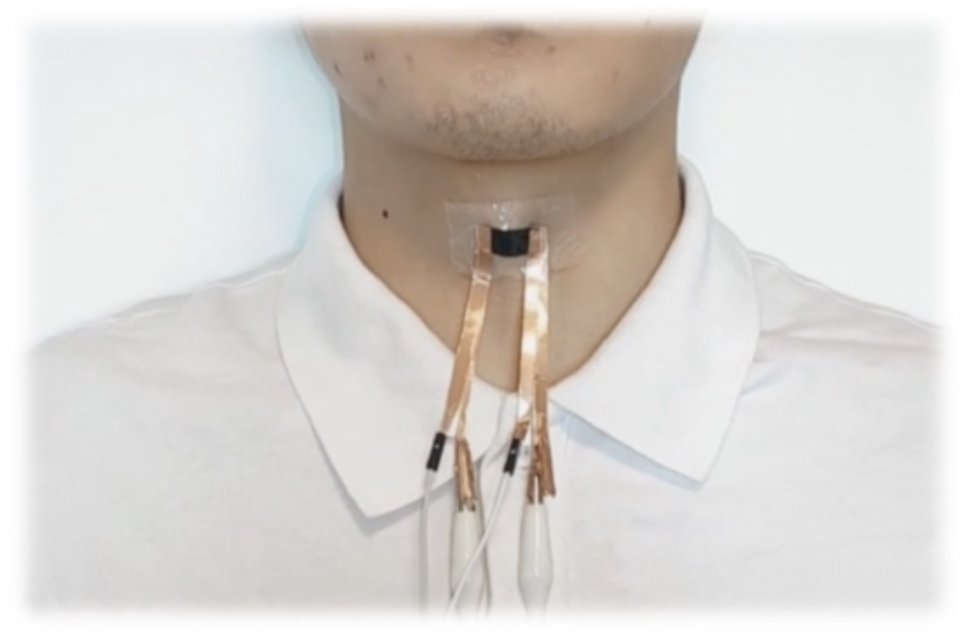
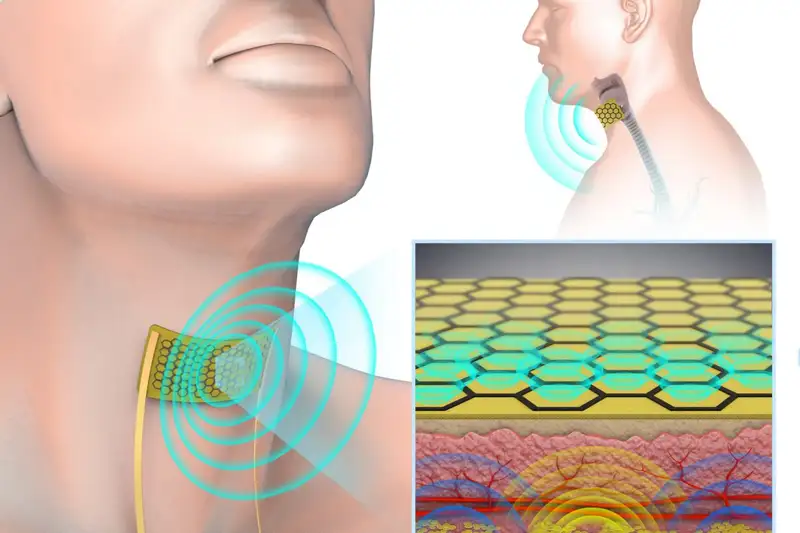
937
スマホで“ひそひそ声”を通常の声に変える技術 東大教授「WESPER」開発 itmedia.co.jp/news/articles/… ささやき声,かすれ声などを通常の音声にリアルタイム変換する機械学習モデル。動画でその違いを確認されたい。
938
見ている画像を脳活動から画像生成AIが高品質に再現 フランスの研究者ら「Brain-Diffuser」開発 levtech.jp/media/article/… 画像を見せた際の脳活動(fMRI信号)から潜在拡散モデル(Versatile Diffusion)含むモデルでその画像に類似した画像を生成。図で性能を確認されたい。左端が元画像,残りが生成画像


939
画像生成AIを「トロイの木馬」で攻撃してみた 生成時に攻撃者が望む画像を出力 米研究者ら「TrojDiff」開発 levtech.jp/media/article/… トロイの木馬に感染させた拡散モデルはユーザーが予測したい画像ではなく攻撃者が予測させたい画像が生成される。攻撃成功は98%以上。


940
QRコードにレーザーを当てて「偽装QRコード」に変える攻撃 悪性サイトに誘導 東海大が発表 itmedia.co.jp/news/articles/… 読み取る時にだけQRコードに遠隔からレーザ光を当てると別サイトに飛ばせる。図右がレーザ(赤点)を当ててるスマホ越し画像。スマホなしで見ると赤点は見えない。図左は当ててない。

941
育てた人の脳細胞をコンピュータに接続、生きたAI「Brainoware」で学習し数式を解くことに成功 levtech.jp/media/article/… 脳オルガノイドを多電極アレイに乗せて,外部からの電気刺激によって入力を受け誘発された神経活動によって出力を送り訓練データを学習するという。
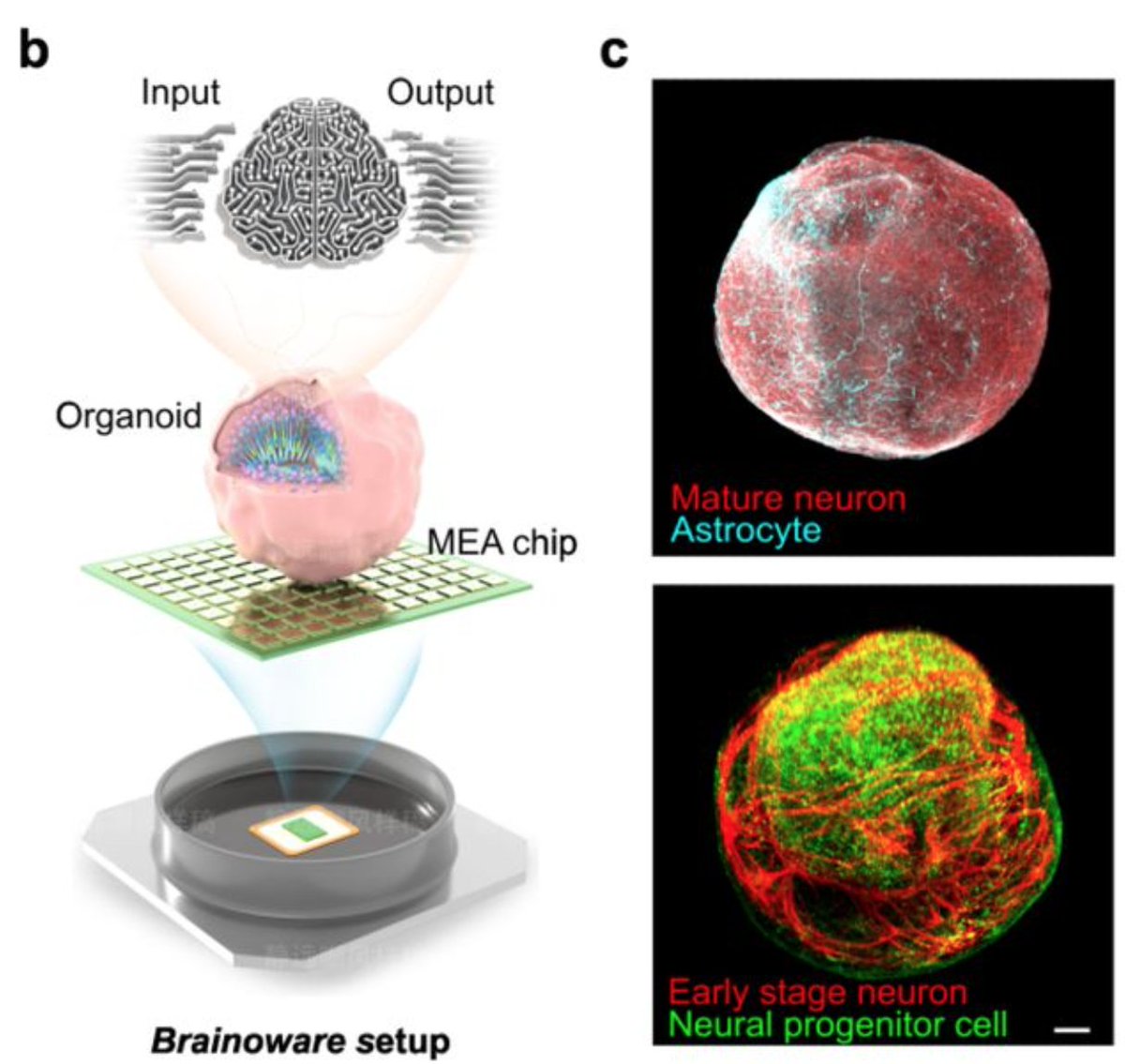
942
YouTubeで“聞こえない音”を流し、スマホを遠隔操作する攻撃 音声アシスタント機能を悪用 itmedia.co.jp/news/articles/… 動画,音楽の裏で聞こえない音(音声コマンド)を流す。聞いた人の周囲のSiri,Alexaが反応。例:PCで動画見る→机上のスマホが反応→ドアロック解除される。Web会議中に会話相手へ攻撃も
943
「AIに毒を盛る」──学習用データを改ざんし、AIモデルをサイバー攻撃 Googleなどが脆弱性を発表 itmedia.co.jp/news/articles/… ネット公開データを大量学習するモデルを攻撃。方法は期限切れのドメイン購入で改ざん,Wikipedia改ざんで攻撃。人種や性差別バイアスの悪化,バックドアを仕込みモデルを制御等

944
1発の注射で大量の薬を埋め込み、時間差で放出する技術 数週間から数カ月先までコントロール可能 itmedia.co.jp/news/articles/… 皮下注射で必要な場所に多くの薬を注入, 薬剤を体内に置き,3日後,5日後,10日後のように各薬剤を時間差放出できる。
945
25人のAIが一緒に暮らしたら、自我は芽生えるか? ゲームの中で検証 バレンタインなど勝手に企画 itmedia.co.jp/news/articles/… ChatGPT等で制御した2Dキャラ25人がレトロRPG風の町で一緒に生活。各キャラが個性や目標を持ち交流し人格があるかのように独立し創発的な行動を繰り広げる。動画デモあり。
946
痛みなしで薬物投与できる薄型パッチ 超音波を利用 米MITなどが開発 itmedia.co.jp/news/articles/… テープなしで皮膚に貼り付けられる薄い小型デバイス,超音波で皮膚を通過させて必要な場所にピンポイントで薬物投与する。痛みがないため気がつかないうちに投与できる。
947
動画を見るマウスの脳活動から映像をAIで復元 スイスの研究者ら「CEBRA」開発 itmedia.co.jp/news/articles/… 30秒600フレームのモノクロ映像をマウスに9回見せプローブを刺した脳から採取した信号と映像をマッピング学習。10回目の脳活動から映像を復元すると95%以上の精度で深層学習モデルが再構築に成功
948
床に物が無くなるまで動く全自動お片付けロボット「TidyBot」 どこに何を収納するかは言語モデルで学習 levtech.jp/media/article/… 人それぞれ収納スタイル(収納場所や収納方法)は違う。これらを文章でGPTを学習させ個人に最適化。引き出しを開け入れて閉める。籠に投げて入れる等。未見の物体で精度91%
949
スマホの充電器から“人間のような音声”を発声、音声アシスタントにこっそり入力するサイバー攻撃 itmedia.co.jp/news/articles/… 攻撃信号を電流に変調し電力網を介して電化製品(PC,TV,充電器等)に内蔵のスイッチング電源に注入。スイッチング電源から合成音声コマンドを発声させ音声アシスタントを制御する
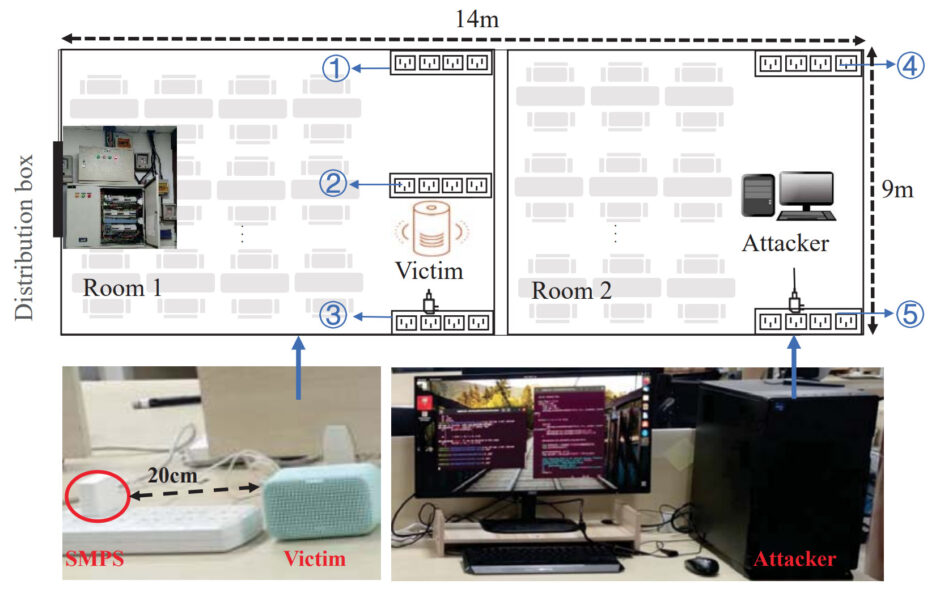
950
音楽から3Dアバターのダンスを高品質に自動生成するAI スウェーデンの研究者らが技術開発 levtech.jp/media/article/… 音楽を入力に3Dアバターの高精度ダンスを生成する拡散モデル。音楽に合わせた格闘技の動作も。鳥やゾンビの真似をしながら歩くことも可能。