51
「他人の“顔”で動画配信」——リアルフェイスマスクを映像内の動く自分に滑らかに適合できる技術 ディズニーなどが開発 levtech.jp/media/article/… 映像内の人顔を違う顔にすり替える技術。顔のみの合成,つなぎ目や照明が自然に統合され違和感少ない仕上がりに。頭部を動かしても歪みが少なく調和をキープ
52
テキストから音楽を生成するAI github.com/MubertAI/Muber…
53
たった1枚の画像からシャープな3Dモデルを自動生成 Google「3DiM」開発 levtech.jp/media/article/… 拡散モデルを用い、1枚の画像から画像に写るオブジェクトの新規ビューを生成し3Dオブジェクトを合成する手法。歪みやぼやけが少ない高品質な仕上がりに。
54
「エサを与えないと動かない」──粘菌搭載型スマートウォッチ 米シカゴ大が開発 itmedia.co.jp/news/articles/… 粘菌は機器内の少し離れた2ヵ所に組み込まれ,水や麦を与えると乾燥(休眠)から覚醒し合体し始め、合体すると回路となり電気が流れデバイスが機能(心拍計測)。餌ないと休眠,あるとまた復活し駆動
55
画像生成AIが“ロボットの動き”を生成 英ICL「DALL-E-Bot」開発 itmedia.co.jp/news/articles/… ロボが目の前を撮影し入力テキストを予測,DALL-E 2に渡し自然で人間らしい配置を表す画像を生成してもらう。その画像でロボットが物を移動させる。画像生成モデルのきちんと整頓した画像を生成する性質を活用。
56
指先の熱からパスワードを盗む攻撃 入力後のキーボードから押した場所を特定 6文字なら検出精度100% itmedia.co.jp/news/articles/… 押したキーの場所を熱画像と深層学習で特定。入力後20秒で86%,30秒で76%の精度で解読。6文字パスワードで100%,16文字で67%。キーキャップ素材はPBTよりもABSの方が脆弱



57
顔のみをアニメ風にして動画配信。動く人の顔を高品質に漫画化するスタイル転送技術 levtech.jp/media/article/… ポートレートビデオ内の人物のアイデンティティーを維持しながら顔をアニメ風に変換する深層学習を用いた技術。動きによって起こるちらつきや歪みを抑えて高解像度での出力を実現。
58
文章から“VRシーン”を作成するAI 4K解像度でHDRパノラマを出力 シンガポールのチームが発表 itmedia.co.jp/news/articles/… テキストから低ダイナミックレンジ/低解像度の360度パノラマをCLIPで生成しダイナミックレンジと解像度の両方を同時に向上させ出力。生成したシーンの部分的編集も可能。
59
ゴキブリを自動で見つけレーザーで殺す装置 数万円で自作も可能 itmedia.co.jp/news/articles/… Gがカメラに映ると物体検出モデルで位置特定,2枚の反射鏡を駆動させレーザー光を制御しGに追従しながら照射。1.6Wで当て続け無効化に成功。GitHabで公開中。約250ドルで自作可能。
60
広い間隔で並ぶと、行列の待ち時間は短く感じる? 東大がVR上で検証 itmedia.co.jp/news/articles/… 行列の主観的な待ち時間が前の人との間隔の広さで変化するかを3つの条件(0.5m,1.0m,2.0m)で比較検証を行った。結果,0.5mよりも1mの方が主観的な待ち時間が短くなった。
61
カメラに「存在しないもの」を見せるサイバー攻撃 離れた場所から電波を送信 成功率は99% itmedia.co.jp/news/articles/… 画像を電磁波でワイヤレス注入,干渉でCCDイメージセンサを攻撃。字が読めるほど鮮明に本来写らない画像を映し出す。バーコードスキャナに攻撃し99%でスキャンミスを起こさせた。


62
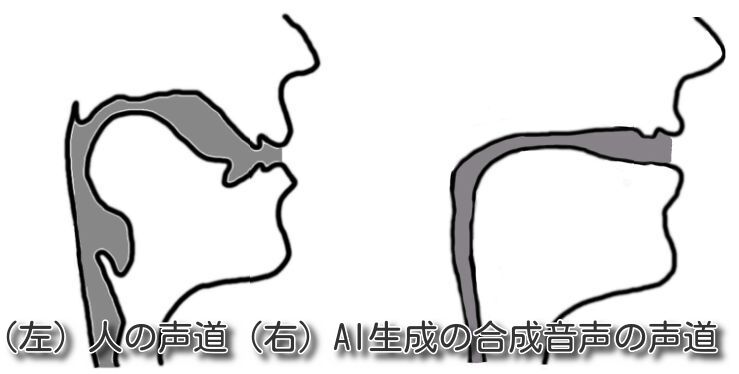
AIが生成した“偽音声”を見抜く技術 99%以上の精度で検出 itmedia.co.jp/news/articles/… 音声から提案モデルで「声道」を生成しその違いでディープフェイク音声かを見抜く。偽声は声道がストローみたいに均等で細く人間と異なるため精度は99.9%。上司の偽声で部下に資金送金させる被害も実際にあった。
63
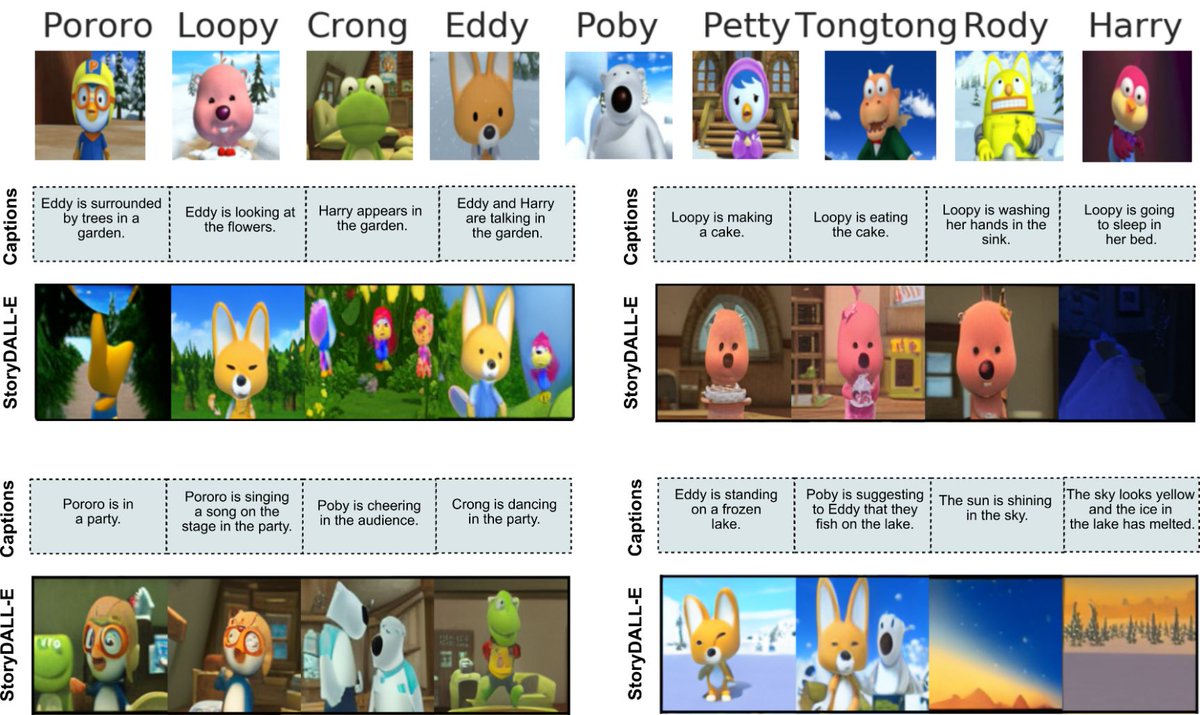
画像生成AIで漫画っぽい物語が作れるモデル「StoryDALL-E」 itmedia.co.jp/news/articles/… テキストから画像を生成できるモデルを改良。背景と登場人物をある程度固定したセリフなし漫画(ビジュアルストーリー)画像群を文章から自動生成できるモデル。連続した画像は背景と人が一貫して出力される。

64
「舌打ち」で障害物の位置を特定 音の跳ね返りをVR上で可視化、エコロケーションを体験 itmedia.co.jp/news/articles/… 舌打ちの反響音で周囲を把握する視覚障害者は実在する。舌打ち音が黄玉となり発射され障害物に跳ね返りそれを見て物体を認識し暗闇部屋を脱出する。コウモリ,イルカの特殊能力を疑似体験
65
メガネの反射からWeb会議中の画面を盗み見る攻撃 閲覧中のサイトを特定する精度は94%以上 itmedia.co.jp/news/articles/… ビデオ会議中の眼鏡に反射する画面内を分析する攻撃。720pのWebカメラで28pt文字を75%以上で認識。カメラが4Kになれば16ptでも。顔の前にライトを置く,眼鏡にぼかしを入れる等で対策

66
文章からアバターの動きを生成するAI「MotionDiffuse」 シンガポールと中国の研究者らが開発 levtech.jp/media/article/… 単語ではなくある程度の文章量からデジタルキャラの動きを自動作成できるテキストtoモーション拡散モデル。パーツ指定や長い時間動かすことも可能。
67
ソーシャルVRで初対面から友人関係がどう築かれるか? 東大が調査 itmedia.co.jp/news/articles/… 実社会と異なり容姿や身分を隠し自分を表現できるソーシャルVR,友達へと発展するプロセス,関係性も異なる。その違いを分析した本研究,そこには相手情報の不確かさを受け入れた匿名コミュニティが成立していた


68
3Dモデルの質感を好きな画風に変えられるスタイル変換モデル NVIDIAなどが開発 levtech.jp/media/article/… ある静止画像の画風を別の3Dオブジェクトの質感に転写する学習モデル。OpenAIのCLIPとNeural style transferを最近傍特徴マッチングで組み合わせた手法。
69
服に敷いた線路をシュッシュッポッポ 体中を移動する小型ロボット 健康状態をモニタリング itmedia.co.jp/news/articles/… 衣服上の線路を移動する小型ロボ。全身を移動でき胸まで移動し心拍を計測、肘に行き筋トレの動きを追跡。線路を磁石で引っ付け上着とズボンを横断。着用者以外の線路への移動も可能
70
漫画で見たくない“地雷シーン”を事前に警告する技術 明治大が開発 itmedia.co.jp/news/articles/… 見たくないシーンを登録しながら漫画を読む。次に出てくる見たくないシーンのページ前に警告される(出てくる位置と嫌な内容が表示)読者はページ送り目をつむる等で回避。見たくないシーンは次の読者と共有も




71
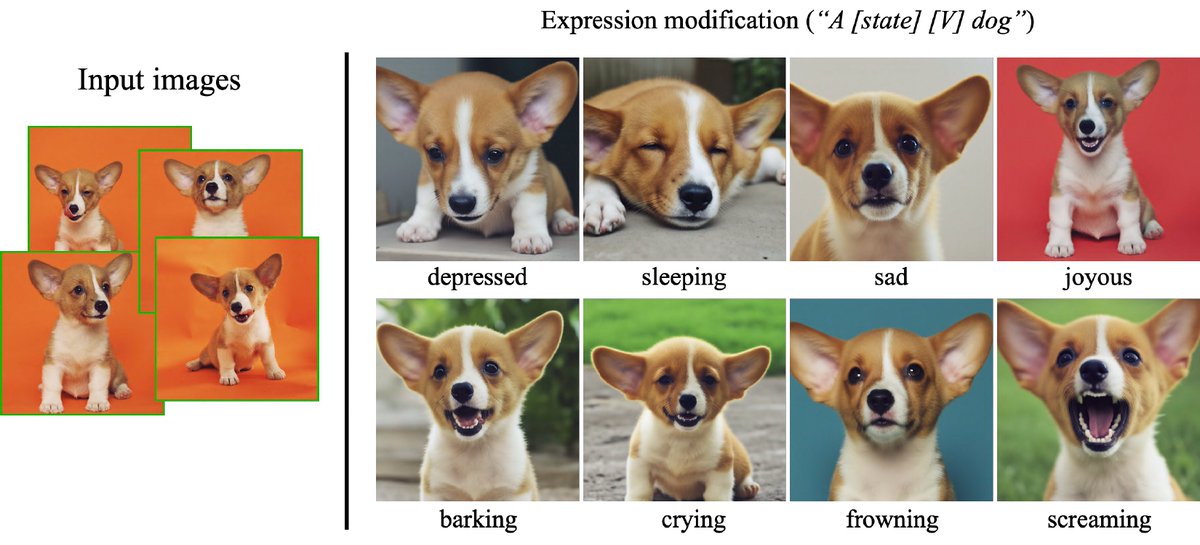
愛犬の合成画像を生成できるAI 文章で指示するだけでコスプレ 米Googleが開発 itmedia.co.jp/news/articles/… 撮影した被写体(人,動物,モノ等)の画像5枚程+テキスト入力=画像生成AIが被写体ベースの合成画像を出力。被写体を泳がす,服を着せる,眠らせる,悲しませる,猫風,ポーズ指定などの合成が高品質に可



72
ネットに接続していないPCをハッキング 超音波で機密データを盗む攻撃 イスラエルの研究者が発表 itmedia.co.jp/news/articles/… 予め仕込んだマルウェアがエアギャップPC内のデータを符号化して超音波で放出。近くのスマホ(8m以内)が内蔵ジャイロで音を振動で受信。スマホから攻撃者に無線伝送で盗完了。
73
1枚の写真から作成する動くメガピクセル頭部アバター。ロシアチームが開発 levtech.jp/media/article/… 写真内の頭部や表情を動かすディープフェイク。既存手法では最大解像度512×512だったが1024×1024での出力に成功。ちらつきはあるがリアルタイムに精密に動く。高解像度の静止画像と蒸留を学習に追加。
74
尾行を検知するラズパイ自作装置 周囲のスマホをスキャン、20分間検出され続けると警告 itmedia.co.jp/news/articles/… Wi-Fi/Bluetooth接続を探している周囲のスマホやタブレットをスキャンし20分間検知が続くと尾行と判断し警告。機器はケースに収納でモバイル化。200米ドル。米国土安全保障省職員が開発

75
画像1枚から永久に続く“空飛ぶシーン”を作れる技術 Googleなどが開発 levtech.jp/media/article/… 複数画像や動画,カメラポーズは不要に画像1枚から空を高速で飛ぶ視点の映像を連続的に自動生成してくれる学習モデル。