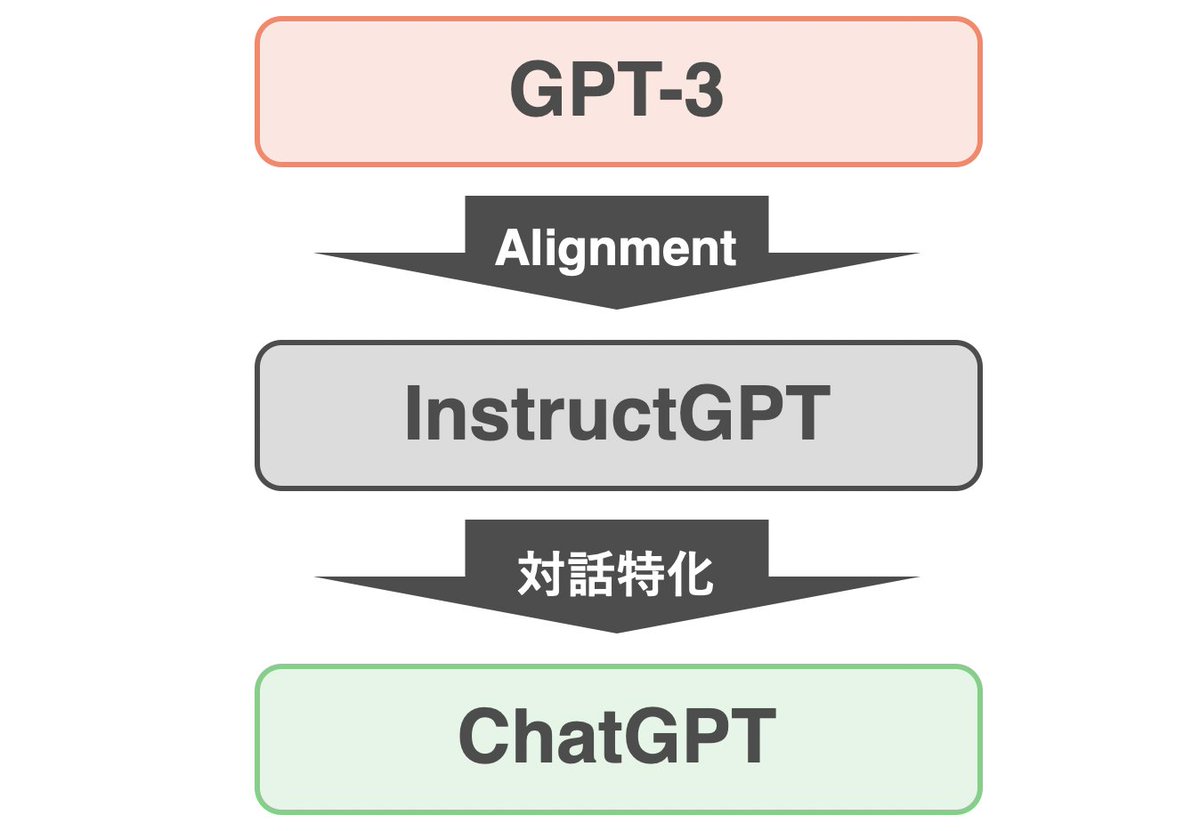
1
ChatGPTの学習方法について解説記事を書きました!
qiita.com/omiita/items/c…
ChatGPTでは、「人間のフィードバックに基づく強化学習(RLHF)」という手法を用いて、GPT-3.5を微調整しています。記事の中では、RLHFやInstructGPTについて解説しています。ぜひご覧ください。
#ChatGPT



2
世界に衝撃を与えた画像生成AI「Stable Diffusion」の解説記事を書きました!
qiita.com/omiita/items/e…
さまざまなテキストから自由自在に画像を生成してしまうStable Diffusion。その仕組みからアーキテクチャまで図をふんだんに使って詳しく説明しています。ぜひご覧ください!




3
これは必見。StanfordからついにTransformerの講義が公開されます。(毎週1つずつ公開予定のようです。)
講義はTransformerから始まり、GPT-3やViT、Switch Transformerなど様々なTransformerの解説をしてくれるようです。
Website: web.stanford.edu/class/cs25/ind…
YouTube: youtube.com/watch?v=P127jh…
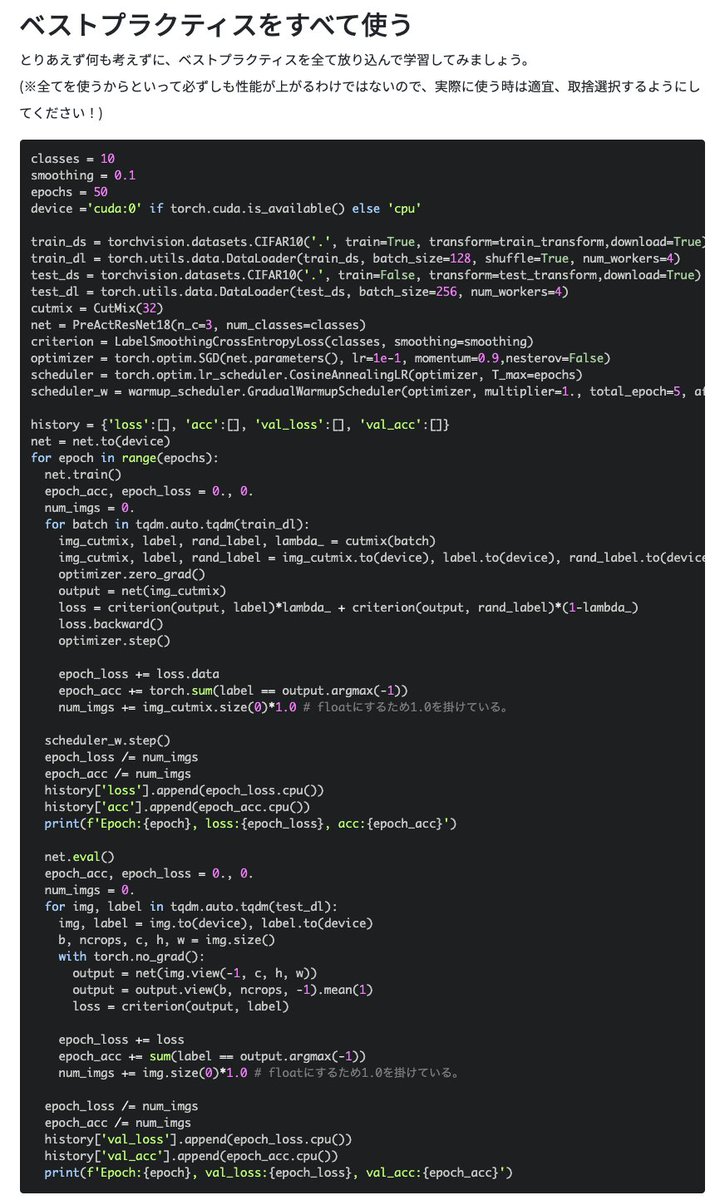
4
深層学習モデルの性能向上のためのオレオレベストプラクティスを10個まとめました!
axross-recipe.com/recipes/116
全てのテクニックにPyTorchによる実装を載せ、全てを用いたコードも示しました。いずれもコンペではよく用いられるものばかりで、あと少し精度を上げたいという方はぜひご一読ください!



5
ディズニー顔へ瞬時に変換するAI!噂のToonify論文の解説を書きました!
qiita.com/omiita/items/5…
仕組みはわずか3ステップという単純さで、浮世絵の写真化など発想もとても面白いです。Toonify Yourself!というサイト(記事内リンク)でも簡単に試せます。ぜひご一読ください!
#深層学習 #機械学習




6
ついに画像認識でもTransformerがCNNを駆逐してしまうかもしれません。
qiita.com/omiita/items/0…
話題爆発中のモデル「Vision Transformer(ViT)」についての解説記事を書きました。ViTは畳み込みを一切使わずに画像識別タスクの幅広いデータセットでSoTAを達成しています。ぜひご覧ください!




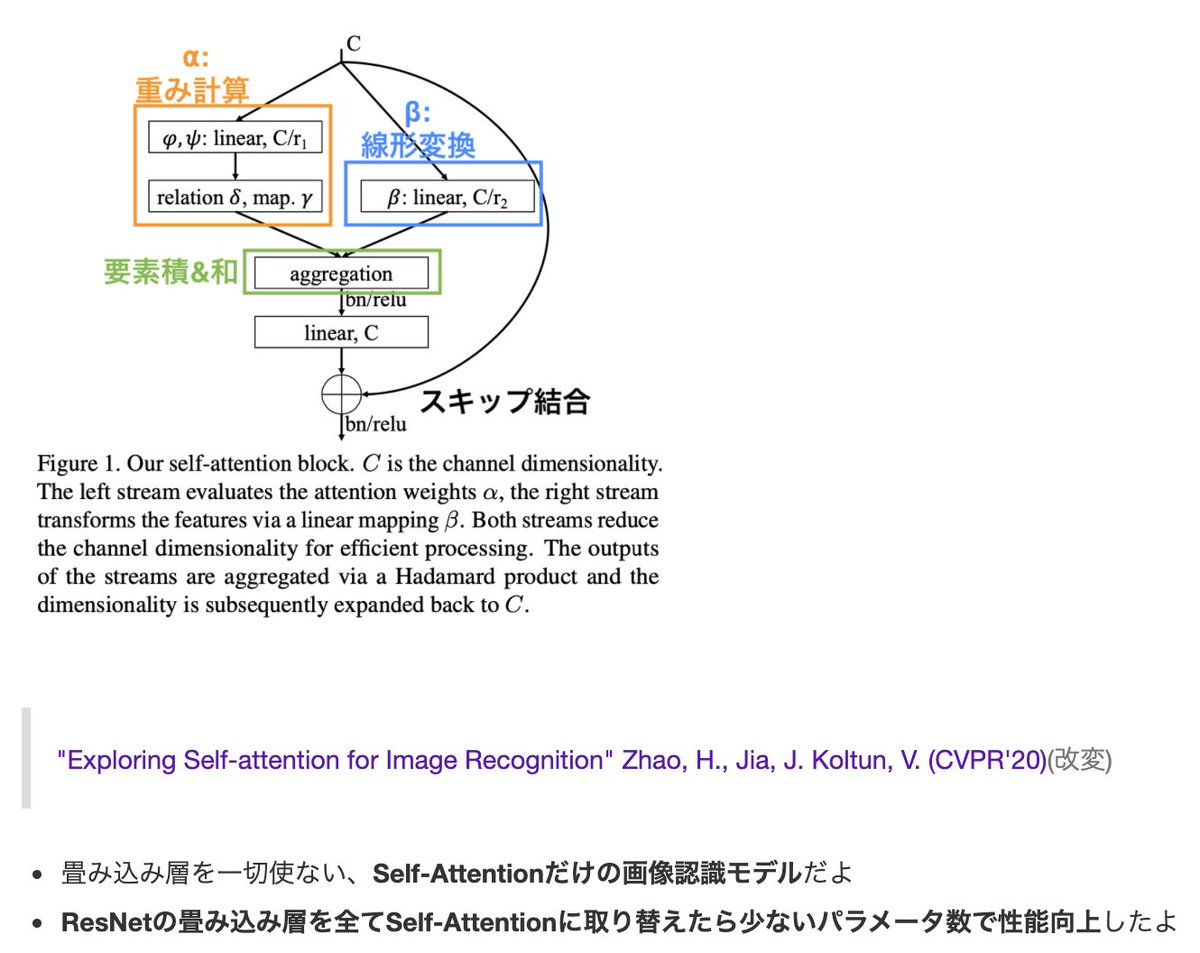
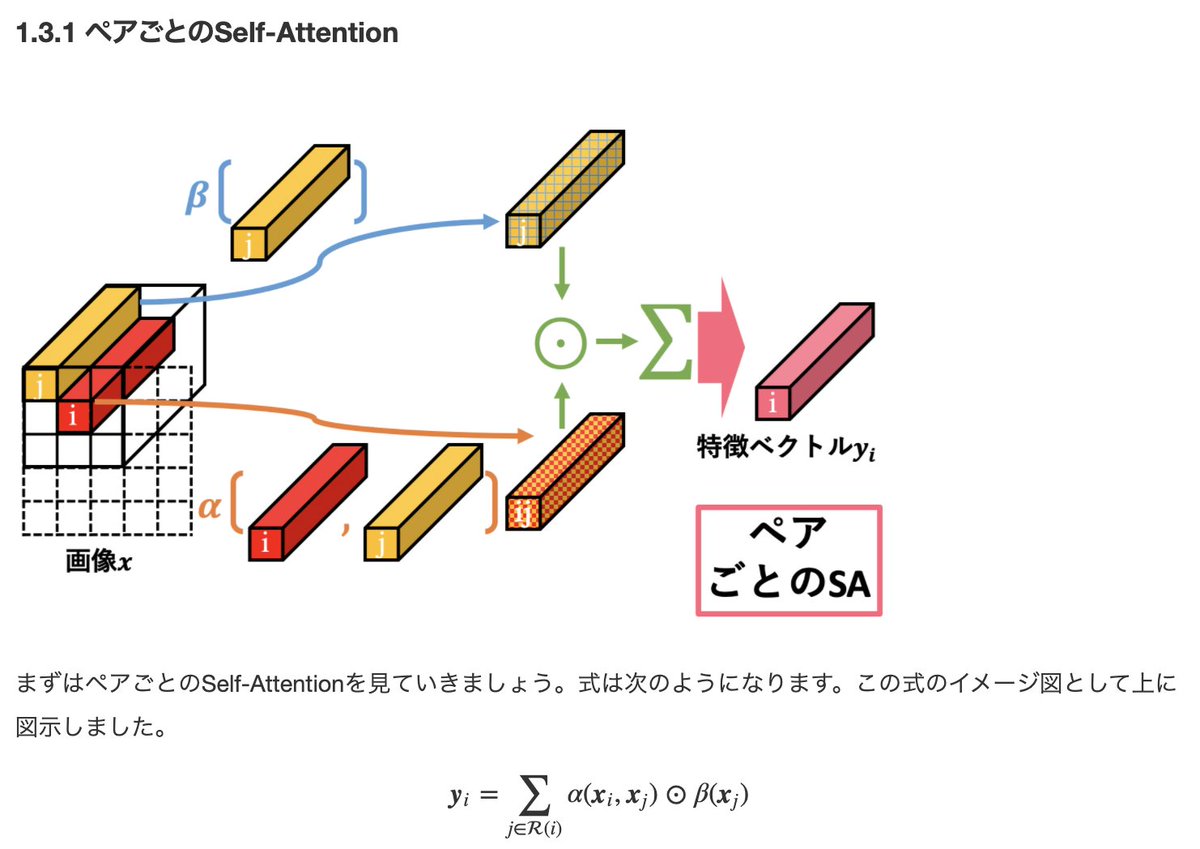
7
畳み込みよ、さようなら。畳み込み層を全てSelf-Attentionに取り替えた新時代のモデル「SAN」の解説記事を書きました!
qiita.com/omiita/items/f…
SAだけで従来のCNNよりも優れた精度/ロバスト性を示しており、画像認識でも遂にSAによる革命が始まりそうです。ぜひご覧ください!
#深層学習 #機械学習


MLエンジニア / M. Eng. / 本書き「Vision Transformer入門(共著)」(amazon.co.jp/dp/4297130580) / 記事書き(qiita.com/omiita)